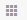
写在前面
下面的这篇文章将手把手教大家搭建一个简单的股票舆情分析系统,其中将先通过金融界网站爬取指定股票在一段时间的新闻,然后通过百度情感分析接口,用于评估指定股票的正面和反面新闻的占比,以此确定该股票是处于利好还是利空的状态。
1
环境准备
本地环境:
Python 3.7IDE:Pycharm
库版本:
re 2.2.1lxml 4.6.3requests 2.24.0aip 4.15.5matplotlib 3.2.1
其中用到了百度的ai接口,通过pip安装的方式如下:
pip install baidu-aip
然后,导入需要用到的所有库:
import requestsimport matplotlib.pyplot as pltimport pandas as pd from lxml import etree from aip import AipNlp
如果大家在学习中遇到困难,想找一个python学习交流环境,可以加入我们的python裙,关注小编,并私信“01”即可进裙,领取python学习资料,会节约很多时间,减少很多遇到的难题。
2
代码实现
1、获取新闻数据
首先,我们需要通过金融界(
http://stock.jrj.com.cn/share)的网站爬取股票的新闻信息。获取指定股票的新闻资讯的接口形式是:
http://stock.jrj.com.cn/share,股票代码,ggxw.shtml如:http://stock.jrj.com.cn/share,600381,ggxw.shtml
如600381股票的新闻资讯如下图所示:
需要注意的是,当获取后面几页的新闻时,其接口需要加一个后缀,形式如下:
http://stock.jrj.com.cn/share,600381,ggxw_page.shtml如获取第二页,http://stock.jrj.com.cn/share,600381,ggxw_2.shtml
首先,我们定义一个函数,传入一个股票代码的列表,表示用于下载到本地的股票新闻的代码。然后将每个股票的代码拼接到api中,然后调用parse_pages()函数用于爬取该api下网页中的数据。
# 下载指定的股票的新闻数据def download_news(codes): for code in codes: print(code) url = "http://stock.jrj.com.cn/share," + str(code) + ",ggxw.shtml" parse_pages(url, code)
接下来,我们实现上面的parse_pages()函数。其中需要先获取每一页新闻数据的总的页数,然后针对每一页拼接对应的api接口,最后再对每一页的新闻数据进行下载。
# 解析每个页面的数据def parse_pages(url, code): max_page = get_max_page(url) for i in range(1, max_page + 1): if i != 1: url = "http://stock.jrj.com.cn/share," + str(code) + ",ggxw_" + str(i) + ".shtml" download_page(url, code)
获取最大页数的函数如下,其中用到了lxml下的etree模块来解析html代码,然后通过正则表达式获取最大页数。
# 获取url下的最大page数def get_max_page(url):
page_data = requests.get(url).content.decode("gbk")
data_tree = etree.HTML(page_data) if page_data.find("page_newslib"):
max_page = data_tree.xpath("//*[@class=\"page_newslib\"]//a[last()-1]/text()") return int(max_page[0]) else: return 1接下来实现download_page()函数,它的作用通过正则表达式匹配页面中的新闻标题,并将获取的标题数据保存到本地文件中。
# 解析指定页面的数据并保存至本地def download_page(url, code):
try:
page_data = requests.get(url).content.decode("gbk")
data_tree = etree.HTML(page_data)
titles = data_tree.xpath("//*[@class = \"newlist\"]//li/span/a/text()") for title in titles:
title = title + "\r\n"
with open(str(code) + ".txt", "a") as file:
file.write(title)
file.flush() return
except:
print("服务器超时")接下来,通过调用上面的download_news()函数,并传入需要爬取新闻的股票代码列表,就可以将新闻数据爬取到本地了。
codes = [600381, 600284, 600570, 600519, 600258, 601179]download_news(codes)
得到的新闻数据形式如下图所示:

2、新闻情绪分析以及统计
在获取了股票的新闻数据之后,我们接下来需要对每支股票的所有新闻进行情感分析了。其中用到了百度人工智能接口aip下的aipNLP用于对所有新闻数据进行自然语言处理,并进行情感分析。需要注意的是,在通过百度人工智能接口进行情感分析之前需要先注册并获取APP_ID、API_KEY以及SECRET_KEY。获取的方式如下:
首先,登录并注册百度人工智能平台(https://ai.baidu.com/):

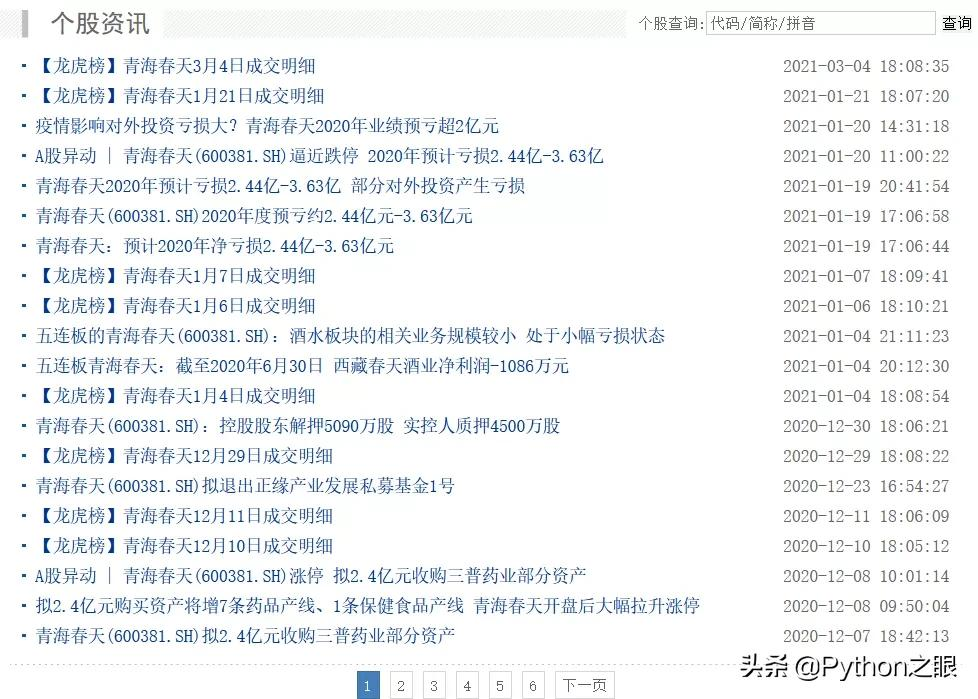
然后,在自己的控制台中找到自然语言处理,并创建应用,如下图所示:
创建完成之后就可以得到自己的APP_ID、API_KEY以及SECRET_KEY,如下图所示:

接下来通过一个函数来实现对指定的股票进行情感分析并保存到本地:
# 对指定的股票进行情感分析并保存到本地def analyze_stocks(codes):
df = pd.DataFrame() for code in codes:
print(code)
stock_dict = analyze(code)
df = df.append(stock_dict, ignore_index=True)
df.to_csv('./stocks.csv')其中的analyze()函数实现如下,其中需要将前面申请的APP_ID、API_KEY以及SECRET_KEY进行定义。之后读取包含每个股票的所有新闻的文件,其中每一行表示一个新闻标题。然后通过aipNLP对每个标题进行情感分析,进而基于得到的分析结果来统计积极新闻和消极新闻的个数,最后将针对每支股票的分析结果返回:
# 对指定股票的所有新闻数据进行情感分析并进行统计def analyze(code):
APP_ID = 'your app id'
API_KEY = 'your api key' SECRET_KEY = 'your secret key'
positive_nums = 0
nagative_nums = 0
count = 0
aipNlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) lines = open(str(code) + '.txt').readlines() for line in lines: if not line.isspace():
line = line.strip()
try: result = aipNlp.sentimentClassify(line)
positive_prob = result['items'][0]['positive_prob']
nagative_prob = result['items'][0]['negative_prob'] count += 1
if positive_prob >= nagative_prob:
positive_nums += 1
else:
nagative_nums += 1
except:
pass
avg_positive = positive_nums / count
avg_nagative = nagative_nums / count
print('股票代码:',code, '消极比例:', avg_nagative, '积极比例:',avg_positive) return {'股票代码':code, '消极比例':avg_nagative, '积极比例':avg_positive}调用下面的代码进行分析,并生成统计结果:
codes = [600381, 600284, 600570, 600519, 600258, 601179]analyze_stocks(codes)
3、数据可视化
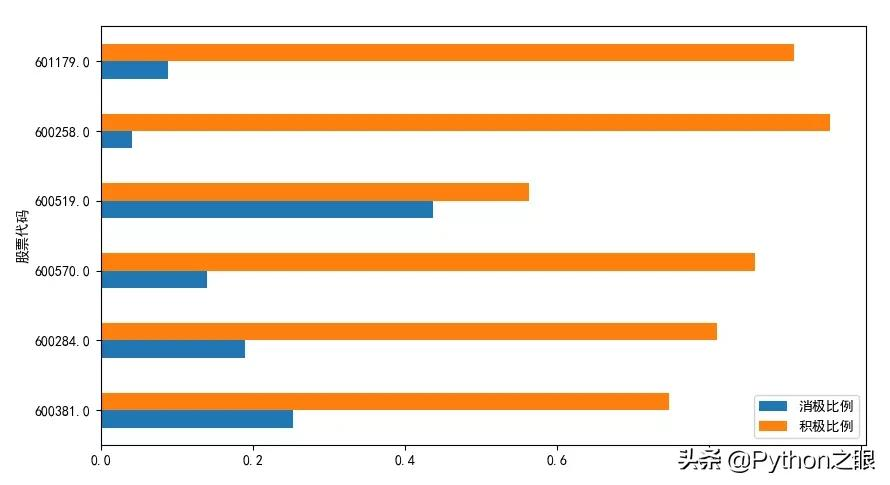
最后我们将得到的结果进行可视化,可以直观地看到每支股票的消极新闻和积极新闻所占的比例。
def show():
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
df = pd.read_csv('./stocks.csv', index_col='股票代码', usecols=['股票代码', '消极比例','积极比例'])
df.plot(kind='barh', figsize=(10, 8))
plt.show()效果图如下所示:
3
总结
在这篇文章中,我们介绍了如何基于python搭建一个简单的股票舆情分析系统,其中将先通过金融界网站爬取指定股票在一段时间的新闻,然后通过百度情感分析接口对新闻进行情感分析,最后统计股票的正面和反面新闻的占比,以此确定该股票是处于利好还是利空的状态。基于此系统,大家可以进行进一步的进行扩展与应用。
来源:技术君